Spheriq AI fonctionne comme un système de pipeline guidé, ce qui rend sa construction plus complexe que celle d’un chatbot qui s’improvise librement. Cette architecture est essentielle si l’on veut que l’IA soit utilisée de manière fiable, peu gourmande en données et traçable dans le secteur associatif. Cet article de fond explique pourquoi et comment Spheriq AI fonctionne avec des lanceurs d’invitations et un pipeline à huit niveaux.
La plupart des outils d’IA commencent par un champ de saisie vide. Les utilisateurs doivent savoir eux-mêmes quelles informations sont pertinentes, comment formuler la question, quelles données ils peuvent insérer et comment la réponse doit être vérifiée à la fin. Cela peut suffire pour des tâches générales et ponctuelles. Pour les tâches quotidiennes de collecte de fonds, de promotion ou de vérification des demandes, cela ne suffit pas.
Pourquoi un chatbot ne suffit pas
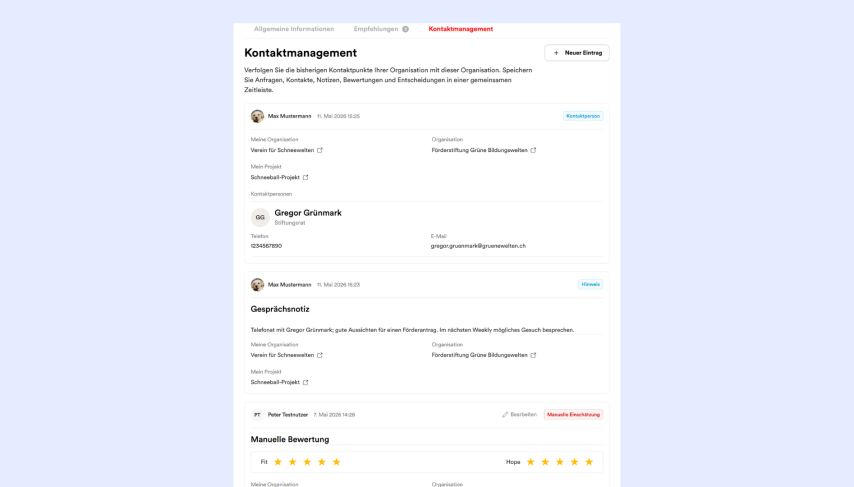
Spheriq AI travaille avec des données institutionnelles publiques, mais aussi confidentielles. Il s’agit par exemple de données de projets qui ne sont pas encore publiques, de demandes, de documents stratégiques ou de données personnelles. Ces données ne sont visibles que pour certains utilisateurs et rôles, et ce pour une bonne raison. Une IA qui ne connaît pas précisément l’ensemble des données n’est pas d’une grande utilité. Et un copier-coller manuel devient vite fastidieux et risqué.
Spheriq est avant tout une boîte à outils. L’utilité se développe au quotidien et dans un contexte de travail concret. Une question posée sur un profil d’organisation peut suggérer une réponse différente de celle posée dans une recherche, sur un projet, dans une liste soigneusement construite ou dans une demande très avancée. Spheriq AI doit donc non seulement comprendre la question, mais aussi prendre en compte le lieu de la demande, le rôle de l’utilisateur et donc le but de chaque étape de travail.
Des lanceurs précis plutôt que des tours de passe-passe
C’est pourquoi l’IA de Spheriq est souvent lancée dans la vie quotidienne par des « lanceurs ». Ce sont des points d’entrée prédéfinis directement dans le contexte de travail, par exemple pour le matching, l’amélioration du profil ou la recherche de subventions. De cette façon, les utilisateurs n’ont pas besoin d’apprendre à écrire une invite d’IA qui fonctionne bien. Ils choisissent une action appropriée et Spheriq AI prend en charge le contexte actuel.
Un lanceur est plus qu’un bouton. Il contient une logique professionnelle : que doit-on vérifier ? Quelles données peuvent être utilisées ? S’agit-il de son propre profil, d’une organisation externe, d’un projet, de critères d’éligibilité ou d’une recherche ? Spheriq AI ne part donc pas de zéro, mais d’une mission guidée.
Les huit étapes du pipeline
En cliquant sur le lanceur ou en envoyant un prompt individuel, le pipeline de Spheriq AI démarre. Il est divisé en huit étapes distinctes, dont certaines sont à nouveau divisées en sous-étapes individuelles. Chaque étape a sa propre tâche et réduit un risque différent : mauvais contexte, mauvais accès aux données, preuves incomplètes, réponses génériques ou conclusions non compréhensibles.
1. planification
Le pipeline classifie d’abord l’intention de la demande. Il distingue par exemple s’il s’agit d’une auto-analyse, d’un matching, d’une recherche de financement ou d’une analyse de documents. En même temps, il sépare le point de départ et l’objectif de la demande (« scope » et « target »). Cela semble plus simple que cela ne l’est dans la pratique, car la direction de la recherche dépend fortement du contexte. Faut-il évaluer son propre profil, le comparer à celui d’un autre ou vérifier l’adéquation de ce dernier ? Une « analyse des requêtes » minutieuse permet de s’assurer que les jalons sont posés correctement. Elle permet d’éviter qu’une analyse de profil soit considérée comme un matching. Cela ouvre la voie aux étapes suivantes.
2. préparer l’utilisation des outils
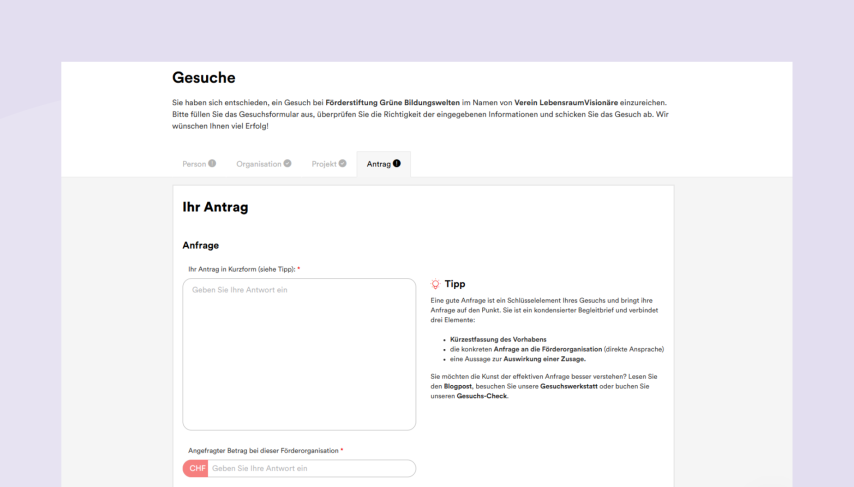
Des outils concrets seront utilisés ultérieurement sur la base du plan. Ces outils ont toutefois besoin d’instructions claires : Quelles organisations sont concrètement recherchées dans organization_search ? S’agit-il de thèmes, de groupes cibles ou de domaines d’action ? En bref, les paramètres des outils doivent être préparés dans la « résolution des arguments des outils ». Il s’agit notamment des identifiants d’entités, des filtres de recherche, des catégories ou des préférences en matière d’évidence. Cette étape est particulièrement importante pour les recherches : Lorsqu’une organisation à but non lucratif recherche des organismes de financement appropriés, le type de recherche, les thèmes, les groupes cibles et le domaine d’impact doivent être correctement déduits et codés.
3. appeler des outils
Les outils nécessaires sont maintenant utilisés. Le pipeline récupère donc de manière autonome des profils, des résultats de recherche, des contenus de listes ou des documents, en plusieurs étapes partielles pour les bases de données volumineuses. Les données, documents et résultats de recherche retournés sont ensuite mis sous une forme structurée afin de pouvoir être interprétés et traités proprement lors des étapes suivantes. Cette sous-étape est appelée « préparation de l’élément de collecte ».
4. sélectionner les candidats
La table est maintenant mise – mais tous les résultats n’ont pas la même importance pour la suite du traitement. Dans le cas de grandes quantités de résultats, le pipeline filtre et hiérarchise les éléments récupérés dans une étape suivante. Les résultats faibles ou non pertinents sont alors éliminés afin de ne pas alourdir l’analyse ultérieure. Cette « sélection des candidats » s’oriente sur le point de départ et l’objectif de la requête : lors d’une recherche de subventions, par exemple, d’autres signaux comptent que lors d’une vérification de profil ou d’un résumé de document.
5. vérifier l’intention
La sélection de la cible est une étape de contrôle importante : le pipeline vérifie une nouvelle fois si la bonne entité cible ou collection cible a été trouvée. Il distingue également les correspondances exactes des correspondances partielles et vérifie si les correspondances attendues sont totalement absentes. Elle vérifie donc si le point de départ et la cible ont été correctement résolus. Cette étape permet d’éviter qu’une réponse ne soit créée sur une base erronée ou seulement apparemment appropriée.
6. condenser les bases
A ce stade, la quantité de données préparées peut encore être très importante : Des dizaines de résultats de recherche et des centaines de milliers de caractères dans des documents chargés sont prêts pour l’analyse. C’est pourquoi le « Batch Reducer » permet maintenant de comprimer des ensembles de résultats plus importants. Comme il s’agit d’une étape intermédiaire délicate, une étape de travail ultérieure, appelée « Exact Collection Rewrite », garantit que les preuves pertinentes sont conservées et que la méthode de comptage est correcte. Le résultat est que la base de la réponse est maintenant disponible de manière compacte. Cela garantit que l’IA ne se contente pas de « nager » dans une énorme quantité de données, mais qu’elle peut travailler avec une base d’évidences ordonnée.
7. évaluation
Bien entendu : Ce n’est qu’à ce stade que commence l’évaluation technique proprement dite. Le pipeline interprète maintenant les preuves et évalue, sur la base de la question posée, ce qui est « fort », ce qui est « faible », ce qui va vraiment ensemble ou quelles conclusions peuvent être tirées des informations disponibles. C’est là que le savoir-faire spécifique à la philanthropie entre en jeu : les logiques d’encouragement, le fit, l’espoir, les badges, la qualité du profil, le matching, l’examen préalable des demandes ou les critères d’encouragement ne sont pas simplement évalués de manière générique, mais selon une logique proprement construite (voir à ce sujet la partie 3 de la série de fond : les clés de l’IA). Une première version de la réponse est alors créée dans le « Final Answer Builder », mais elle est généralement plus détaillée que nécessaire et, surtout, elle n’est pas encore condensée de manière cohérente dans le format de sortie souhaité.
8. réponses
Enfin, la réponse est nettoyée dans le « Final Answer Rewrite » et adaptée au format souhaité. La langue et le format de sortie sont vérifiés, les détails internes sont supprimés et les incohérences sont corrigées (Final Answer Repair). C’est essentiel, car les logiques de réponse diffèrent selon les cas d’utilisation. Une analyse de profil, par exemple, nécessite une structure différente de celle d’un matching, d’une évaluation par badge ou d’un résumé des critères d’éligibilité. C’est pourquoi le pipeline ne se contente pas de fournir une réponse, mais assure un format adapté. L’ancrage dans les preuves disponibles est également contrôlé une nouvelle fois ici (vérificateur). Si nécessaire, le pipeline revient sur les étapes précédentes. La réponse finale doit être compréhensible, concise, utile et compréhensible : sans argot d’IA, sans exagération et sans flatterie (la fameuse « sycophonie »).
Le pipeline de l’IA Spheriq n’est pas une fin en soi. Il remplit plusieurs fonctions à la fois : il contrôle l’accès aux données, réduit les hallucinations, renforce la traçabilité et assure l’application cohérente de concepts spécifiques à la philanthropie. Il permet également de détecter à temps les informations manquantes, contradictoires ou inaccessibles et de les identifier clairement, plutôt que de combler les lacunes par des suppositions. Le pipeline est donc plus qu’une simple production rapide de textes.
Spheriq AI suit ainsi les principes dont on parle aujourd’hui sous des termes tels que « Responsible AI » ou « Explainable AI » : L’IA doit apporter un soutien, limiter l’accès aux données, rendre les réponses compréhensibles et ne pas remplacer la responsabilité humaine. Les lignes directrices de la Commission européenne sur l’IA de confiance s’attaquent également à ce point : Surveillance humaine, robustesse technique, protection des données, transparence et responsabilité.
Ce que les utilisateurs retirent de cette architecture
Pour les utilisateurs, le pipeline signifie avant tout moins de travail à l’invite, des contextes plus précis et des réponses plus spécifiques et plus compréhensibles. Lorsque Spheriq AI utilise des documents en plus des profils d’organisation ou de projet, ceux-ci sont listés et résumés à la fin de la réponse. Cela permet de garder une trace des éléments sur lesquels l’évaluation est basée.
En bref, les utilisateurs de Spheriq AI ne doivent pas avoir à se demander quelles données peuvent être copiées ou comment une question technique précise doit être structurée. Le lanceur et le pipeline prennent le relais, mais l’utilisation reste flexible. Après une réponse, le travail peut se poursuivre dans le chat et les résultats peuvent être approfondis, raccourcis ou retravaillés.
Certes, le pipeline rend l’IA plus lente que certains chatbots généraux. En même temps, il la rend plus fiable, plus précise et plus stable. Et c’est là que réside son objectif. Il ne s’agit pas d’une réponse d’IA improvisée à la va-vite, mais d’une assistance guidée, vérifiable et contextualisée pour le travail quotidien dans le secteur à but non lucratif.